lxw1234[一起学Hive]系列文章总结。
一、Hive概述,Hive是什么
1. Hive是什么
Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
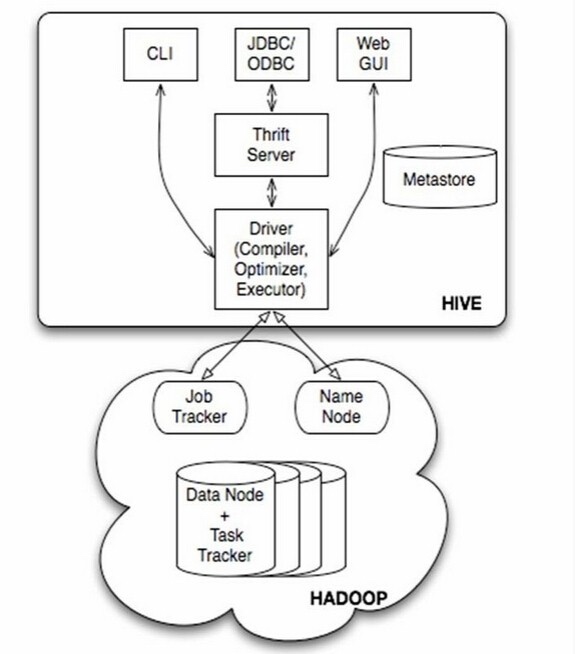
如图中所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
2. Hive擅长什么
Hive擅长的是非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即席查询,统计分析。
3. Hive的数据单元
- Databases:数据库。概念等同于关系型数据库的Schema,不多解释;
- Tables:表。概念等同于关系型数据库的表,不多解释;
- Partitions:分区。概念类似于关系型数据库的表分区,没有那么多分区类型,只支持固定分区,将同一组数据存放至一个固定的分区中。
- Buckets (or Clusters):分桶。同一个分区内的数据还可以细分,将相同的KEY再划分至一个桶中,这个有点类似于HASH分区,只不过这里是HASH分桶,也有点类似子分区吧。
4. Hive的数据类型
4.1 原始数据类型
- 整型
TINYINT — 微整型,只占用1个字节,只能存储0-255的整数。 SMALLINT– 小整型,占用2个字节,存储范围–32768 到 32767。 INT– 整型,占用4个字节,存储范围-2147483648到2147483647。 BIGINT– 长整型,占用8个字节,存储范围-2^63到2^63-1。 - 布尔型
BOOLEAN — TRUE/FALSE - 浮点型
FLOAT– 单精度浮点数。 DOUBLE– 双精度浮点数。 - 字符串型
STRING– 不设定长度。
4.2 复合数据类型
- Structs: 一组由任意数据类型组成的结构。比如,定义一个字段C的类型为STRUCT {a INT; b STRING},则可以使用a和C.b来获取其中的元素值;
- Maps: 和Java中的Map没什么区别,就是存储K-V对的;
- Arrays: 就是数组而已;
二、Hive函数大全-完整版
现在虽然有很多SQL ON Hadoop的解决方案,像Spark SQL、Impala、Presto等等,但就目前来看,在基于Hadoop的大数据分析平台、数据仓库中,Hive仍然是不可替代的角色。尽管它的相应延迟大,尽管它启动MapReduce的时间相当长,但是它太方便、功能太强大了,做离线批量计算、ad-hoc查询甚至是实现数据挖掘算法,而且,和HBase、Spark都能整合使用。
主要目录如下,具体详情参照:Hive函数大全-lxw1234.co
2.1 关系运算:
- 等值比较: =
- 等值比较:<=>
- 不等值比较: <>和!=
- 小于比较: <
- 小于等于比较: <=
- 大于比较: >
- 大于等于比较: >=
- 区间比较
- 空值判断: IS NULL
- 非空判断: IS NOT NULL
- LIKE比较: LIKE,通配符匹配(_和%),否定形式A [NOT] LIKE B
- 正则RLIKE操作: RLIKE,内部java正则 实现
- REGEXP操作: REGEXP,同RLIKE
2.2 数学运算:
- 加法操作: +
- 减法操作: –
- 乘法操作: *
- 除法操作: /
- 取余操作: %
- 位与操作: &
- 位或操作: |
- 位异或操作: ^
- 位取反操作: ~
2.3 逻辑运算:
- 逻辑与操作: AND 、&&
-
逻辑或操作: OR 、 - 逻辑非操作: NOT、!
2.4 复合类型构造函数
- map结构
- struct结构
- named_struct结构
- array结构
- create_union
2.5 复合类型操作符
- 获取array中的元素
语法:A[n] 操作类型:所有基础类型 说明:返回数组 A 中第 n 个索引的元素值。 - 获取map中的元素
语法:M[key] 操作类型:所有基础类型 说明:返回 map 结构 M 中 key 对应的 value。 - 获取struct中的元素
语法:S.x 操作类型:所有类型 说明:返回 struct 结构 S 中名为 x 的元素。
2.6 数值计算函数
- 取整函数: round
- 指定精度取整函数: round
- 向下取整函数: floor
- 向上取整函数: ceil
- 向上取整函数: ceiling
- 取随机数函数: rand
- 自然指数函数: exp
- 以10为底对数函数: log10
- 以2为底对数函数: log2
- 对数函数: log
- 幂运算函数: pow
- 幂运算函数: power
- 开平方函数: sqrt
- 二进制函数: bin
- 十六进制函数: hex
- 反转十六进制函数: unhex
- 进制转换函数: conv
- 绝对值函数: abs
- 正取余函数: pmod
- 正弦函数: sin
- 反正弦函数: asin
- 余弦函数: cos
- 反余弦函数: acos
- positive函数: positive
- negative函数: negative
2.7 集合操作函数
- map类型大小:size
- array类型大小:size
- 判断元素数组是否包含元素:array_contains
- 获取map中所有value集合:map_values(Map<K.V>),返回值array<V>
- 获取map中所有key集合:map_keys(Map<K.V>)
- 数组排序:sort_array(Array<T>)
2.8 类型转换函数
- 二进制转换:binary
- 基础类型之间强制转换:cast,cast(expr as <type>)
2.9 日期函数
UNIX时间戳与日期函数互转
- UNIX时间戳转日期函数: from_unixtime
- 获取当前UNIX时间戳函数: unix_timestamp
- 日期转UNIX时间戳函数: unix_timestamp
- 指定格式日期转UNIX时间戳函数: unix_timestamp
select from_unixtime(1323308943,'yyyyMMdd') from lxw1234; select unix_timestamp() from lxw1234; select unix_timestamp('2011-12-07 13:01:03') from lxw1234;转换格式为"yyyy-MM-dd HH:mm:ss"的日期到 UNIX 时间戳。如果转化失败,则返回0。 select unix_timestamp('20111207 13:01:03','yyyyMMdd HH:mm:ss') from lxw1234; - 日期时间转日期函数: to_date
- 日期转年函数: year
- 日期转月函数: month
- 日期转天函数: day
- 日期转小时函数: hour
- 日期转分钟函数: minute
- 日期转秒函数: second
- 日期转周函数: weekofyear
- 日期比较函数: datediff
- 日期增加函数: date_add
- 日期减少函数: date_sub
- date类型与datekey类型转换函数: date2datekey/datekey2date,2019-10-10转20191010
2.10 条件函数
- If函数: 语法, if(boolean testCondition, T valueTrue, T valueFalseOrNull)
- 非空查找函数: COALESCE
- 条件判断函数CASE: 语法,CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
2.11 字符串函数
- 字符ascii码函数:ascii
- base64字符串
- 字符串连接函数:concat
- 带分隔符字符串连接函数:concat_ws
- 数组转换成字符串的函数:concat_ws
- 小数位格式化成字符串函数:format_number
- 字符串截取函数:substr,substring
- 字符串截取函数:substr,substring
- 字符串查找函数:instr
- 字符串长度函数:length
- 字符串查找函数:locate
- 字符串格式化函数:printf
- 字符串转换成map函数:str_to_map
- base64解码函数:unbase64(string str)
- 字符串转大写函数:upper,ucase
- 字符串转小写函数:lower,lcase
- 去空格函数:trim
- 左边去空格函数:ltrim
- 右边去空格函数:rtrim
- 正则表达式替换函数:regexp_replace
- 正则表达式解析函数:regexp_extract
- URL解析函数:parse_url
- json解析函数:get_json_object
- 空格字符串函数:space
- 重复字符串函数:repeat
- 左补足函数:lpad
- 右补足函数:rpad
- 分割字符串函数: split
- 集合查找函数: find_in_set
- 分词函数:sentences
- 分词后统计一起出现频次最高的TOP-K
- 分词后统计与指定单词一起出现频次最高的TOP-K
2.12 混合函数
- 调用Java函数:java_method
- 调用Java函数:reflect
- 字符串的hash值:hash
2.13 XPath解析XML函数
- xpath
- xpath_string
- xpath_boolean
- xpath_short, xpath_int, xpath_long
- xpath_float, xpath_double, xpath_number
2.14 汇总统计函数(UDAF,User-Defined Aggregation Funcation)
-
个数统计函数: count
语法: count(*), count(expr), count(DISTINCT expr[, expr_.]) 说明: count(*)统计检索出的行的个数,包括NULL值的行; count(expr)返回指定字段的 非空值的个数; count(DISTINCT expr[, expr_.])返回指定字段的不同的非空值的个数 - 总和统计函数: sum
语法: sum(col), sum(DISTINCT col) 说明: sum(col)统计结果集中 col 的相加的结果; sum(DISTINCT col)统计结果中 col 不同值 相加的结果 - 平均值统计函数: avg
- 最小值统计函数: min
- 最大值统计函数: max
- 返回组内某个数字列的方差: variance(col),var_pop(col)
- 返回组内某个数字列的无偏样本方差: var_samp
- 总体标准偏离函数: stddev_pop
- 样本标准偏离函数: stddev_samp
- 中位数函数: percentile
- 近似中位数函数: percentile_approx
- 直方图: histogram_numeric
- 集合去重数:collect_set
语法: collect_list (col) 返回值: array 说明: 将 col 字段进行去重,合并成一个数组。 - 集合不去重函数:collect_list
语法: collect_list (col) 返回值: array 说明: 将 col 字段合并成一个数组,不去重
2.15 表格生成函数(UDTF: User-Defined Table-Generating Functions)
- 数组拆分成多行:explode
语法: explode(ARRAY) 返回值: 多行 说明: 将数组中的元素拆分成多行显示 - Map拆分成多行:explode
语法: explode(Map) 返回值: 多行 说明: 将 Map 中的元素拆分成多行显示 举例: hive> select explode(map('k1','v1','k2','v2')) from lxw1234; OK k2 v2 k1 v1
参考
- http://lxw1234.com/archives/tag/learn-hive/page/2
- Hive-LanguageManual
- Hive-Home