总结深度学习中的DNN网络。
神经网络
基本结构
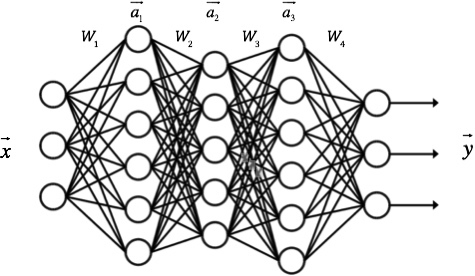
DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。 DNN神经网络在感知机的模型上做了扩展,总结下主要有三点:
- 加入了隐藏层,隐藏层可以有多层,增强模型的表达能力,模型的复杂度也增加了好多。
- 输出层的神经元也可以不止一个输出,可以有多个输出,这样模型可以灵活的应用于分类回归,以及其他的机器学习领域比如降维和聚类等。
- 对激活函数做扩展,感知机的激活函数是, 虽然简单但是处理能力有限,因此神经网络中一般使用的其他的激活函数,Sigmoid函数,tanh, softmax,和ReLU等。通过使用不同的激活函数,神经网络的表达能力进一步增强。
前向传播算法
节点i的输出: $a_i$ 激活函数:sigmoid函数 $\sigma (t) = \cfrac{1}{1 + e^{-t}}$

接着,定义网络的输入向量和隐藏层每个节点的权重向量$\vec{w_j}$。令
代入上式得:
现在,我们把上述计算的四个式子写到一个矩阵里面,每个式子作为矩阵的一行,就可以利用矩阵来表示它们的计算了。令
最终得到某一层的输出表示,这就是前向传播:
应用上式,如下举例:
反向传播算法(Back Propagation)
反向传播算法其实就是链式求导法则的应用。然而,这个如此简单且显而易见的方法,却是在Roseblatt提出感知器算法将近30年之后才被发明和普及的。对此,Bengio这样回应道:
很多看似显而易见的想法只有在事后才变得显而易见。
激活函数$f$:sigmoid函数 每个训练样本:$(\vec{x},\vec{t})$ 误差平方和作为目标函数,$E_d$表示是样本$d$的误差:
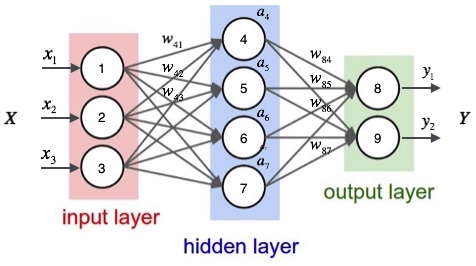
观察上图,我们发现权重$w_{ji}$仅能通过影响节点j的输入值影响网络的其它部分,设$h_j$是节点$j$的加权输入,即
$E_d$是$h_j$的函数,而$h_j$是$w_{ji}$的函数。 根据链式求导法则,可以得到:
上式中,$x_{ji}$是节点$i$传递给节点$j$的输入值,也就是节点$i$的输出值。
对于$\cfrac{\partial{E_d}}{\partial{h_j}}$的推导,需要区分输出层和隐藏层两种情况。
输出层权值训练
对于输出层来说,$h_j$仅能通过节点$j$的输出值$y_j$来影响网络其它部分,也就是说$E_d$是$y_j$的函数,而$y_j$是$h_j$的函数,其中$y_j=\sigma(h_j)$。所以我们可以再次使用链式求导法则:
考虑上式第一项:
考虑上式第二项:
将第一项和第二项带入,得到:
如果令$\Delta_j=-\cfrac{\partial{E_d}}{\partial{h_j}}$,也就是一个节点的误差项$\Delta$是网络误差对这个节点输入的偏导数的相反数。带入上式,得到:
将上述推导带入随机梯度下降公式,得到:
上式就是式5。
隐藏层权值训练
现在我们要推导出隐藏层的$\frac{\partial{E_d}}{\partial{h_j}}$。
首先,我们需要定义节点j的所有直接下游节点的集合$Downstream(j)$简写$DS(j)$。例如,对于节点4来说,它的直接下游节点是节点8、节点9。可以看到$h_j$只能通过影响$DS(j)$再影响$E_d$。设$h_k$是节点$j$的下游节点的输入,则$E_d$是$h_k$的函数,而$h_k$是$h_j$的函数。因为$h_k$有多个,我们应用全导数公式,可以做出如下推导:
因为$\Delta=-\cfrac{\partial{E_d}}{\partial{h_j}}$,带入上式得到:
上式就是式4。